
 TC
304
TC
304
Source: TC304 PT on the Guide
Date: 26 Feb 1999
Status:
CEN TECHNICAL REPORT Draft 2 for CEN Trnnnn:1999 1999-02-22 Descriptors: Data processing, information interchange, text processing, text communication, graphic characters, character sets, representation of characters, coded character sets, architecture Information Technology - Guide to the use of character set standards in Europe This CEN Technical Report has been drawn up by CEN/TC 304 This CEN Technical Report was established by TC 304 in one official version (English). A version in any other language made by translation under the responsibility of a CEN member into its own language and notified to the Central Secretariat has the same status as the official version. CEN members are the national bodies of Austria, Belgium, the Czech Republic, Denmark, Finland, France, Germany, Greece, Iceland, Ireland, Italy, Luxembourg, Netherlands, Norway, Portugal, Spain, Sweden, Switzerland, and the United Kingdom. CEN European Committee for Standardization Comité Européen de Normalisation Europäisches Komitee für Normung Central Secretariat: rue de Stassart 36, B-1050 Brussels © CEN 1999 Copyright reserved to all CEN members Ref.No. TR xxxx:1999 E This report was produced by a CEN/TC 304 Project Team, set up in June, 1998, as one of several to carry out the funded work program of TC 304 (documented in CEN/TC 304 N 666 R2). A first draft was discussed at the TC meeting in Brussels in November, 1998. This revised draft is circulated for comments within the TC. A final draft will be presented for approval at the next TC plenary meeting (April, 1999). The approved version will then be sent to the CEN BT for approval.
TABLE OF CONTENTS
FOREWORD
*Guide to the use of character sets in Europe
*1 Introduction
*2 Executive summary
*3 Scope and field of application
*4 Definitions
*5 Characters and their coding
*5.1 Characters, glyphs and languages
*5.2 Coding
*5.3 Control functions and control characters
*6 The character handling model
*6.1 The input function
*6.2 The processing function
*6.3 The interchange function
*6.4 The output function
*6.5 Cultural issues
*7 Official standards, manufacturer standards, and related standards
*7.1 Telecommunication standards
*7.2 Manufacturer standards
*7.3 Related Standards
*8 International character sets
*8.1 Framework standards for 7- and 8-bit environments
*8.2 7- and 8-bit character set standards
*8.3 The universal character set (UCS) standard
*8.4 Control functions
*9 European character sets
*9.1 8-bit character sets
*9.2 The multilingual European subsets
*9.3 The Euro sign
*10 Procurement issues
*10.1 Repertoires and code structures
*10.2 Transformation and fall-back
*10.3 Code structure interoperability
*11 Procurement clauses
*11.1 Structure
*11.2 Input character repertoire
*11.3 Output character repertoire
*11.4 Processing character repertoire
*11.5 Interchange character repertoire
*11.6 Additional requirements when using the 8-bit code structure for interchange
*11.7 Additional requirements when using the multi-byte UCS code structure for interchange
*12 CEN and CEN/TC 304
*13 References
*
There exist today a large number of standards and related specifications concerning character repertoires and their coding in the form of official as well as manufacturer standards and intended for a wide range of applications and uses. Furthermore, there are character set standards for data communication and there are standards developed specifically for telecommunications applications. The situation can be very confusing to the non-expert user and to people involved in procurement.
The user of IT systems normally does not have to concern himself with these types of standards. However, there may be situations where he has to be able to express his needs for certain character repertoires necessary for his work; it may also happen that he, when involved in work together with other parties using other systems, needs to be able to interpret other people's specifications given in the form of reference to standards.
The procurer of IT systems should be able to specify his requirements in the form of reference to established standards.
A particular purpose of the report is to give guidance for public procurement in Europe. Since there is an EC directive and a council decision for such procurement requiring the use of official European standards above certain procurement amounts, the report concentrates on such standards. There may be future editions, in which case more attention will be given other types of standards. (See also section 7.)
The main purpose of this report is to give guidance to users and procurers by explaining the purposes and relationships of the official standards in the domain of data communication. Explicit guidance is given in paragraphs marked with 4 .
The text is presented on two levels. The first level, contained in the body of the report, provides a general coverage of character repertoires, coding and uses. The second level, contained in the two annexes, provides much more detailed, tutorial information. The reader who finds the level of technical detail to deep may be better served by the "Manual: Standards for the electronic interchange of personal data: Part 5 - Character sets" (see References).
Further information on character sets and their standardization can be found in the document "Language automation world-wide: The development of character set standards" and on the Letter Database web site (see References).
The main body of this report is aimed primarily at the non-technical person who needs to become familiar with use of character set standards in Europe for various purposes in an IT environment. This audience will include managers/decision makers and their advisors; administrators (for procurement purposes); technicians (for programming and system development purposes); standardisers; perhaps also journalists.
The concepts of characters and their coding is introduced in section 5, and a conceptual model on the use of coded character sets is provided in section 6. The guide concentrates on official character set standards. However, there is a range of other standards for character sets that are not official, and there are also specifications concerning associated topics such as rules for ordering character strings. Section 7 goes on to place the official standards in the wider context of these other standards. Sections 8 and 9 describe a range of official character set standards with an international and a European scope respectively. Section 10 introduces a number of procurement issues, and section 11 provides sample text that may be used as the basis for inclusion in (public) procurement specifications for IT systems and software.
In addition, the guide has two annexes which contain a much more technical description of official character set standards.
The activities of CEN/TC304, the committee responsible for the promulgation of character set and related specifications in Europe, are described in section 12, and finally pointers for further reading and research are given in section 13.
3 Scope and field of application
The technical scope of this guide is primarily limited to official character set standards promulgated by ISO/IEC and CEN, as opposed to official telecommunications standards and manufacturer standards. However, an overview of all types of standards is given in section 7. The guide furthermore concentrates on European issues; thus character set standards for non-European languages are not covered.
The guide is mainly intended as an introduction for people who need to familiarise themselves with the concept of character sets and their coding; e.g. managers/decision makers and their advisors; administrators (for procurement purposes); technicians (for programming and system development purposes); standardisers; perhaps also journalists. Particular emphasis is placed on its use by procurers.
The following terms are used in the body of this report and the official definitions are given here where they exist. They are taken from the standards ISO/IEC 9541:1991 and ISO/IEC 10646-1:1993, except when denoted by an *.
(character) repertoire: A specified set of characters that are each represented in a coded character set.
control function: An action that affects the recording, processing, transmission, or interpretation of data, and that has a coded representation containing one or more bit combinations.
*Note - A bit combination in this context is a 7- or (more commonly) 8-bit byte.
control character: A control function the coded representation of which consists of a single bit combination.
*Note - A control character is not strictly spoken a "character" but is called that way because its coded representation is of the same type as that of a coded graphical character.
coded character set (character set): A set of unambiguous rules that establishes a character set and the one-to-one relationship between the characters of the set and their coded representation.
*code table: A tabular representation of a coded character set, showing also the coded representations.
*code page: Synonym for code table, used in the IBM environment.
*code space: The numeric domain occupied by all bit combinations used for the coding of a coded character set.
transliteration: The process which consists of representing the characters of an alphabetical or syllable writing system by the characters of a conversion alphabet.
Note - In principle, a transliteration should be a one-to-one conversion.
*fall-back: A non-reversible transformation consisting of the substitution of an output character which cannot be represented on the output device by one or more characters which can.
combining character: A member of an identified subset of a coded character set, intended for combination with the preceding or following graphic character, or with a sequence of combining characters preceded or followed by a non-combining character
*diacritic, diacritic mark: A mark intended for the association with a letter (e.g. acute accent).
glyph: A recognisable abstract graphic symbol which is independent of any specific design.
5.1 Characters, glyphs and languages
For the presentation of written text we use letters, digits and punctuation marks. Often we also use special symbols such as currency signs. All of these are called characters, and the collection of characters for a specific purpose, such as the presentation of text in a specific language, is called in the standardisation context a character repertoire. The most common type of repertoire is of course the alphabet of a language, complemented by the ten digits and a set of special characters.
A character is represented in printed form or on a display surface; hence it must have an agreed shape. Of course, a character may be represented by many variations of its basic shape (or shapes, as with
g and g) depending on the font in use (e.g. Times Roman or Arial). No matter how many such variations may be used to represent a character, the basic shape is always recognisable to the human eye. This inherent shape of a character, which is independent of font, is known as a glyph. However, it should be recognised that this concept is less straightforward than it first might appear. Thus one and the same glyph may represent, in different contexts, different characters (e.g. the Latin character B is not the same as the Cyrillic character B).Although the glyph concept is important for the definition of character repertoires, it is not central to the theme of this guide. The reader who wishes to obtain more information about glyphs is referred to ISO/IEC TR 15285, An operational model for characters and glyphs (see References).
Almost every language has its own character repertoire. However, the fact that many European languages have a large number of characters in common naturally facilitates the work on defining character repertoires for Europe. In CEN/TC 304 there is a separate activity on providing a catalogue of the alphabets of indigenous languages, information on which can be found at http://www.stri.is/tc304/......
In IT systems a character is represented by a 7- or 8-bit combination, usually expressed as a numeric code. A character repertoire with its corresponding set of codes is called a coded character set or just character set. Such a set is often represented graphically in the form of a code table (Figure 1), which also illustrates the principles of the distribution of the codes, the code structure. Furthermore, the totality of the bit combinations used for a coded character set is called its code space.
Figure 2 - Code table.
Coded character sets are used for different purposes in computer systems, and the code structures may therefore vary. For instance, a coded character set used for interchange purposes often needs codes to be reserved for control characters, so that these may be included in the interchange data stream. However, a coded character set used for processing purposes may not need such reserved areas, which instead are often only used to represent more graphic characters. Examples of the latter are the manufacturer standards known as PC code pages.
5.2.1 Proliferation of codes; standardization
Early IT systems had severe size limitations. Therefore, the character codes had to be kept small. The earliest codes occupied 5 and 6 bits; later 7 and 8 bits have been used. These provide a coding capacity for 32, 64, 128 and 256 characters respectively. However, even with an 8-bit representation it is not possible to support all European languages in a single coded character set. Thus coded characters sets proliferated. As long as an application (and the character set it used) was restricted in use to a single country or geographical region, this proliferation did not create problems, since a character set could be chosen to support the limited number of languages for that region. However, due to the requirements of international trade and the increase in travel, the limitation in the number of characters in one coded set has caused great problems of application interoperability.
In order to avoid a very large number of private character set specifications, many with overlapping scope and leading to interoperability problems, standardisation was needed. It was carried out both by the official standardization organisations and by the manufacturers, most notably by IBM, Apple and Microsoft.
Modern IT systems no longer have the earlier restrictions in size, and a solution is now available which uses a code space sufficient to accommodate the characters of every language in the world in one and the same coded character set. However, since the old solutions seem likely to continue to exist until perhaps 2025, the old problem may remain acute for some time. There will be the added complication of using the old and the new systems together as well as how to migrate, in an orderly fashion, to the new system.
5.3 Control functions and control characters
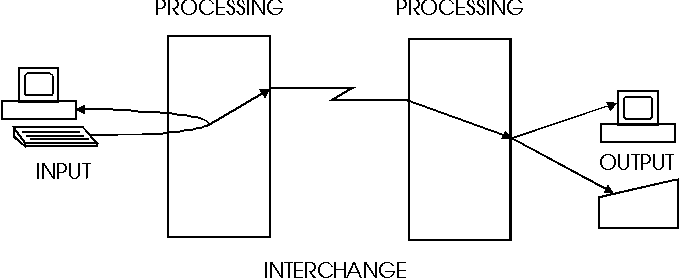
Figure 2 - Character Handling Model
For IT processing purposes, it is necessary to indicate within a data stream where some action is required, e.g. a carriage return or new line. Such actions are performed through control functions, which do not have graphical representations. Over 160 control functions have been standardized. Some of them, such as the carriage return, are represented by a single control character, which, even though it does not have a graphical representation, has a coded representation of that type and can therefore be included in a code table. Others are represented by a sequence of characters with a special introducing control character at the beginning of the sequence.
6 The character handling model
Figure 1 below illustrates the character handling model. It represents a simplified IT scenario which consists of two computer systems connected by a communications link. The purpose is to show the different aspects of the handling of characters by users and computer systems and thus introduce basic concepts that will be used in the following sections of the report. It is also intended to help differentiate between the roles of the user(s) and the procurer in the context of this guide.
The input function provides for the entering of data into a computer system. Figure 2 uses a keyboard for input, but any device capable of entering character data may be used.
Note that the representation of the input text on the monitor screen is a result of both the processing function, e.g. a word processor, and an output function (to the screen).
6.1.1 Keyboards
The main keyboard standard is ISO/IEC 9995, Keyboard layouts for text and office systems. National keyboard standards have, in general, been promulgated based upon this international standard. Keyboard standards are related to character set standards but are not central to the theme of this guide. CEN/TC304 has a separate activity on European keyboard standardisation, information on which may be found at http://www.stri.is/tc304/......
The processing function provides for the manipulation of data according to the needs of an application.
Once input, the data is expressed in some internal computer system code. In addition, other information may be associated with each character such as colour, emphasis level and font. Such information is usually intended for some document processing function. Thus the system internal code structure may be quite complex. However, at its heart is the character code itself; document handling and processing is outside the scope of this guide.
Most commercially available computer systems do not use standardised character sets for internal representation of character data, but proprietary character sets or manufacturer specifications.
6.2.1 Ordering
A particularly common requirement on the processing function is that it be able to order character based data. The main ordering standard is ISO/IEC 14651, International string ordering - Method for comparing character strings and description of a default tailorable ordering. Standards for ordering, while related to character set standards, are not central to the theme of this guide. In CEN/TC 304, there is a separate activity on European standardisation of ordering, information on which may be found at http://www.stri.is/tc304/......
The interchange function provides for the interchange of data between computer systems. Since the character sets for processing are generally defined by manufacturer specifications, they are likely to be different in two different computer systems between which data are to be exchanged. Thus a character set for interchange is needed which will have to be different from one or both of the processing character sets. This is where character set standards become very relevant to reduce the number of interchange character sets - potentially one for every possible pair combination of different computer systems.
The main problem here is that there may not be a one-to-one correspondence between the characters in the character set for processing and those in the character set for interchange. In such cases less than trivial transformation functions are required at the interfaces between processing and interchange; see clause 10.2. Such transformations may incur a loss of information.
The output function is the process of converting the internal coded representations of the characters to a visual representation on a display or hard copy device. The output character sets may be different depending of the output medium.
The handling of output to physical devices is usually an internal computer system function. Application programs, such as word processing packages, normally have the ability to control also the rendition of the output. This includes the use of fonts, both type and size, and also the use of various levels of emphasis and colour. In some cases, information which specifies particular values of these attributes is carried with the individual character codes right from the time of input. As already stated, these features are outside the scope of this guide.
The main problem is when the output character set is smaller than the character set for processing. The computer system software has to substitute one or more characters for those which cannot be represented by the output function (see clause 10.2). Again, such transformations may incur a loss of information.
Each country or region in Europe (and elsewhere) has cultural conventions which affect the manner in which character sets are used by application programs. Such conventions include, but are not restricted to, ordering (already mentioned), numeric formatting, monetary formatting, date and time conventions, affirmative and negative answers, the use of special characters and personal name rules.
Cultural conventions primarily affect the processing function but may also impact the other functions. They are related to the use of character set standards but are not central to the theme of this guide. In CEN/TC304 there is a separate activity on cultural conventions which is developing and maintaining a registry of such conventions. Information may be found at http://www.stri.is/tc304/......
7 Official standards, manufacturer standards, and related standards
There are four main categories of character set standards:
As already explained, this guide concentrates on the first of these categories (but does not cover national standards). In the remainder of this section further information is given on the other categories.
7.1 Telecommunication standards
Character set standards promulgated by ITU-T and by ETSI support applications primarily defined and promoted by the telecommunications companies. Thus for Teletex, Recommendation T.61 was developed. It was subsequently replaced by T.51, which is also used as the basis for character set support in other telematic applications such as the X.400 Message Handling Service and the X.500 Directory Service. There are some links, however, with ISO/IEC standards. T.51 is equivalent to ISO/ IEC 6937 (see section 8); and there is also T.50, equivalent to ISO/IEC 646 (see section 8). This alignment is due to collaboration between the two standards organisations. Nevertheless, ISO/IEC 6937 is used primarily for telematic applications and services.
ETSI has developed character set standards in support of radio paging (ERMES), GSM and RDS, but these standards are not aligned at all with ISO/IEC standards.
Manufacturer standards can be grouped into IBM EBCDIC variants and those in support of personal computers such as the PC and the Macintosh. All use 8-bit codes. The EBCDIC code pages have their own defined structure together with an invariant set of characters and code positions. This is similar in concept to the parts of ISO/IEC 8859 (see section 8). Indeed some EBCDIC code pages have the same repertoire as parts of ISO/IEC 8859, which makes it straightforward to perform mappings between the two environments. Other EBCDIC code pages are designed to support specific countries or regions. More information on this may be found in the IBM document "Character Data Representation Architecture" (see References).
Both IBM and Microsoft have designed PC code pages, and each page is aimed at supporting specific countries or regions. PC code pages do not in general comply with the 8-bit code structure specified in ISO/IEC 2022 (see section 8), and mappings between the two environments may result in the loss of information.
IBM EBCDIC and PC code pages are described in Appendix I of "IBM National Language Support Reference Manual Volume 2" (see References).
The document "Comparisons of Standardized Character Sets for Europe" provides mappings of the differences between various official and manufacturer standards (see References).
In addition to standards on the definition of character repertoires and coding, there are standards relating to the handling of character sets and other character set issues.
Keyboard standards are concerned with the input to computer systems of character information. They cover such topics as keyboard layouts. There is one international standard plus a range of national standards, most of which are based on the international standard.
Ordering standards are concerned with sorting character strings or sets of strings into some order. There is an international standard, and work is under way in Europe on the ordering of European repertoires. A related activity concerns the matching of character strings, for use in, for instance, search engines.
Transformation standards are concerned with rules for mapping the characters from one repertoire onto another, and from one code system onto another. They are sometimes needed when character information from one computer system needs to be transferred into a different computer system due to a mismatch of functionality. An example is the mapping of an official standardised character set onto EBCDIC, so that character based information may be processed in an IBM machine. There are a number of different types of transformation needed for various scenarios. See also clause 10.3.
8 International character sets
This section describes internationally standardised character sets (i.e. both repertoires and coding) used primarily for input (mainly for the specification of repertoires) and interchange. For processing, most IT systems use proprietary manufacturer standards.
Because of the need to combine different standards and also in order to make the standardisation itself more consistent and effective, a common platform standardising the principles for code structure, code extension, implementation and registration has been established. The standards which define that platform may be called framework standards.
The international character set standards in this area may be classified in the following way:
8.1 Framework standards for 7- and 8-bit environments
See also Figure 3 below.
Note - A profile is a selection of options from one or more standards, constituting a more narrow form of specification than the base standard(s) it refers to.
A registration authority allocates values for the escape sequences to be used with the registered coded character set. The registration authority is the Information Processing Society of Japan/Information Technology Standards Commission of Japan (IPSJ/ITSCJ), and the register may be accessed on-line at http://www.itscj. ipsj.or.jp/ISO-IR/. All standardised coded character sets are registered, but not all registered coded character sets are standardised. There are currently over 200 registrations. A coded character set may be identified in text, such as a procurement specification, by the sequence ISO-IR nnn, where nnn is the registration number.

Figure 3 - Overview of framework standards.
8.2 7- and 8-bit character set standards
The set of characters which only includes the non-optional characters is called the Invariant Set. There are default allocations of characters to the optional code positions, and when those are used, the character set is called the International Reference Version (IRV). The IRV is registered as ISO-IR 6. It was changed in the 1991 edition of the standard with the currency sign being replaced by the dollar sign.
The standard also defines a default set of control characters to be used where applicable. The IRV:1991 together with the default control character set is identical to ASCII (American Standard Code for Information Interchange), a name in common usage in the industry. This character set does not contain any letters with accents or diacritical marks. It is therefore unsuitable for use in representing most European languages.
Each part of ISO/IEC 8859 contains a code table made up of two halves (Figure 4). The left half is identical to the graphic characters of the IRV of ISO/IEC 646:1991 coded in 8 bits. The right half is specific to the part in question. Together, the two halves define a self contained 8-bit coded character set of up to 191 characters. There are currently 15 parts to ISO/IEC 8859, falling into two categories. In the first category, containing 9 parts, the second table contains extra Latin characters. The title of each of these parts is Latin Alphabet No. n where n lies in the range 1 to 9. In the second category, the second table contains characters from a non-Latin script. The title of each of these parts is Latin/xxx where xxx is the name of the second script (e.g. Latin/Greek). Each part of ISO/IEC 8859 supports a range of languages. They are listed in Annex A in the section on ISO/IEC 8859.
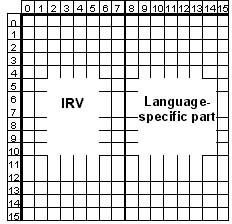
Figure 4 - The two halves of the ISO/IEC 8859 series.
Note - In products supporting ISO/IEC 8859, no code extension is used. However, since the right halves of the code tables - the ones specific to each part of the standard - are all registered, any one of them can form part of larger coded character sets with the use of code extension techniques. For such implementations, reference must be made to the registration number of the code table and not to the corresponding part of the standard.
The merit of this standard is that it specifies a functionality which goes somewhat beyond that of EN 1923 (see clause 9.1) while still using the "old" 8-bit technology.
8.3 The universal character set (UCS) standard
It is obvious that the limitations of both 7- and 8-bit coding create problems in a world where increasingly texts in very different languages need to be communicated between computer systems. Some years ago, the radical step was taken to create a standard with enough code capacity to allow the coding of all alphabets in the world within one framework.
8.3.1 The Basic Multilingual Plane
ISO/IEC 10646 defines a character set and a code structure of up to 4 octets. The main aim was to provide sufficient code capacity so that the alphabets of all the known languages in the world, together with a large range of special characters, could be accommodated. It has to be said that four octets is an overkill, but this was kept to cater for any possible future requirement. It was decided to concentrate at first on populating the lowest two octets of the code space, and this space is known as the Basic Multilingual Plane (BMP).
Since publication, the standard has been subject to a number of amendments, most of which add further language support to the BMP.
It is planned that the BMP will contain all characters, including combining characters, needed to write all the known living languages of the world, with the exception of some of the Chinese and Japanese ideographs. It should be noted that over 27,000 Han characters for Japanese and Chinese are assigned to the BMP, so there is significant support for the languages of those countries which only require a few thousand characters for the large proportion of applications. The BMP certainly already contains all the characters needed for the vast majority of European languages. For this reason, a two octet as well as a four octet representation is specified for use when the application environment only makes use of the BMP. Other coded representations are specified to cater for situations where more than the BMP is used but where better efficiency than use of the four octet form is needed. More detailed technical information may be found in Annex B.
8.3.2 Subsets
A procedure has been agreed for the submission of proposals for the addition of subsets to the base standard. There are several reasons for this. Many systems have quite modest character set requirements, which are application dependent. There are severe restrictions in small implementations such as for mobile telephones, mobile digital radio systems and set top boxes for digital television. Furthermore, there is in Europe a need to identify a character set specifically to support all European languages. Submissions are normally channelled through the national standards organisations.
8.3.3 Unicode
An equivalent but not identical specification to this standard is also published by an industry consortium called UNICODE. Although the two are separately published, every attempt is made to ensure that they are kept in line. In particular, both publications define the characters contained in the Basic Multilingual Plane (BMP).
The UNICODE standard plays an important role from the point of view of procurement. As already noted there have been a number of amendments to ISO/IEC 10646-1, and over the past few years the appearance of amendments has been continuous. The standard changes every time an amendment is ratified. This means that it is not reasonable for suppliersâ implementations to be kept in synchronisation. The UNICODE standard, on the other hand is not changed very often and so suppliers can keep in synchronisation with it. Version 2 of the UNICODE standard is identical position for position with the first edition of ISO/IEC 10646-1 plus its first 7 amendments. Version 3 of the UNICODE standard, due for publication in 1999, will be position for position identical with the second edition of the international standard, which will incorporate the first 31 amendments. These publications represent significant points for the industry to synchronise its products.
This standard was originally defined for use in the 7- and 8-bit code structures. However, ISO/IEC 10646-1 has provisions which allow control functions to be used in the UCS code structure.
In order to provide specifications particularly suited for European applications, CEN has standardised implementations of ISO/IEC standards, including subsets of the UCS standard. CEN promulgates ENs (European Standards) and CWAs (CEN Workshop Agreements). An EN is promulgated by a full CEN Technical Committee and is ratified by a ballot involving the national standard organisations (NSOs) belonging to CEN. A CWA does not carry the authority of a full EN and is promulgated by a Workshop whose membership is open to all comers. A CWA is not subject to NSO ballot; its authority rests on the fact that it is an agreement - and commitment - based on a wide marketplace consensus.
The four repertoires for the Latin script are:
EN 1923 specifies how these repertoires are coded using the extension mechanisms of ISO/IEC 2022:1994, and how they can be combined. A set of combination options is given. (Not all possible combinations are allowed.)
9.2 The multilingual European subsets
The CEN Workshop Agreement (CWA) nnn specifies three subsets of ISO/IEC 10646-1:1993. These are the so called Multilingual European Subsets (MES). The purpose of the CWA is to identify subsets of the BMP for specific use in Europe so that they may be added to the UCS standard.
This CWA is at the time of writing (February, 1999) not finally agreed, which means that its publication in that form is not guaranteed. However, the work towards this particular goal will continue.
MES-3 is defined in two forms: One is a non-fixed subset (MES-3A), which permits automatic inclusion in it of any new characters added to the BMP whose coding positions fall within the collections which define this subset. The other is also the fixed subset (MES-3B), which is invariant over time.
In order to support the move to EMU in the Euro zone of the EU, the Euro sign has now been included in the following of 8-bit code tables.
In all of these, the Euro sign is in the code position usually occupied by the currency sign. The Euro sign is already included in ISO/IEC 10646-1 by amendment 18 and is also included in all three Multilingual European Subsets (MES).
The procurement issues described here are related to specific character handling functions (see section 6).
10.1 Repertoires and code structures
10.1.1 User issues
The user does not need to be concerned with the coded representation of the input character set since a character, once input, has a code defined by the internal processing. What may be an issue here is the specification of the input character repertoire, which must be able to support the user requirements.
For the same reason, neither does the user need to be concerned with the coded representation of the output character set. Again, the repertoire needs to be sufficient to support his requirements. In particular, there should be font support for that repertoire. Character transformation may be an issue if the product cannot support the full output repertoire needed; see clause 10.2.
10.1.2 Procurement issues: Code structure for the interchange function
The procurement issues will centre around the interchange character set. As in the other cases, the repertoire needs to be sufficient to support the requirements of the user. The main issue will be the code structure. The industry is in a state of transition. The 8-bit code structure of ISO/IEC 2022:1994 has been around for some considerable time and is the safe, but limited, option. The future lies with the multi-octet code structure of ISO/IEC 10646-1:1993, but it will not for some time be available in all receiving systems. Still, this guide recommends that new procurements should specify the multi-octet code structure wherever possible. However, there may be cases where the new system has to operate in an environment which overwhelmingly uses 8-bit coding. If so, that code structure should be used. Increasingly, however, there will be situations where the new system has to operate with both code structures, and then the availability of dual support has to be considered.
10.1.3 Procurement issues: Repertoire for the interchange function
If the 8-bit code structure is chosen for the interchange function, this guide recommends that, in Europe, the repertoire(s) are chosen from those identified in EN 1923:1998.
The repertoire selection indicated above is a minimum requirement. The supplier may go further.
10.2 Transformation and fall-back
The choices of repertoires for the four character handling functions described in the model should not be made independently of each other. For instance, a choice of a large processing repertoire such as MES-3 may not be sensible if the interchange repertoire is BL within the 8-bit code structure. It is recommended that, if possible, the same repertoire is used throughout.
If this is not possible, the procurer must specify appropriate transformation, based on the user requirements. This may be done by analysing the interfaces between the character handling functions in the model.
10.2.1 Interfaces
10.2.2 Transformation functions
When a character in one repertoire is not contained in the other, a character transformation is required. The requirements on such a transformation function may vary. For instance, the requirement may be that it is reversible (i.e. it must be possible to reconstruct the original character from its converted form). An example of this would be where the character é is replaced by the HTML representation é. In another case, a non-reversible transformation may be all that is required. Here, characters that are defined in both character sets are passed through whilst other characters may be substituted by some common substitute character, or some approximation may be made (e.g. by replacing é by e and so on).
A particular type of transformation is caused by the situation when the output characters are represented in a different script from the input characters. Transliteration is then required. It is dependent not only on the scripts concerned but also on the languages. Thus the rules for transliteration from Russian is different if the target language is German than if it is French.
In Europe there are five scripts in current use for the indigenous languages: Latin, Greek, Cyrillic, Armenian and Georgian. In CEN/TC 304 there is not at this time any activity devoted to transliteration. Standards in this area are developed by ISO/TC 46 (Information and Documentation).
If the transformation causes loss of information (i.e. it is not reversible), the procedure is called fall-back. The computer system may provide means by which the lost information can be traced (for instance with a "reveal codes" function), but this requires some indication on the output device that such a substitution has actually taken place (e.g. by the use of a specific substitute character, a special level of emphasis or colour).
Another method is a one to many character mapping from which the identity of the original character can be deduced. As an example, élève may be transformed to e/le\ve. However, such a technique can cause problems with tabular formatting of information.
Transformation is related to character set standards but is not central to the theme of this guide. In CEN/TC304 there is separate activity on transformation which is developing a model and is examining various transformation techniques. Information may be found at http://www.stri.is/tc304/......
10.3 Code structure interoperability
A more fundamental issue of interoperability concerns the use of the code structures themselves. Such issues arise at the processing/interchange and interchange/output interfaces. For both the 8-bit code structure and the UCS code structure, many options have to be defined for the receiver to be able to interpret the incoming data stream correctly. For example, in the 8-bit code structure, how will the receiver know which 8-bit character set is used? And in the UCS code structure, how will the receiver know which coding form is used? As a final example, how will the receiver know which code structure is used - 8-bit or UCS?
10.3.1 8-bit interchange code structure
If the 8-bit code structure is being used during interchange either an a priori agreement has to be in place on which character sets and code structure options to use, or the code extension facilities of ISO/IEC 2022:1994 must be used in the exchange to establish such an understanding. In the former case, a higher level protocol may determine the agreement before the interchange of character data takes place - an example is Internet Mail. In the latter case, the detailed conformance requirements on the use of ISO/IEC 2022:1994, as given in ISO/IEC 12070:1996, could be used. However, as has already been indicated, products rarely support the code extension facilities of ISO/IEC 2022:1994, so in most cases the user has to rely on the establishment of a priori agreements (which may be automated).
10.3.2 UCS interchange code structure
For the multi-byte UCS code structure, the following information is needed by the receiving system:
Again, either an a priori agreement is needed, or the designation, identification and signature facilities specified in ISO/IEC 10646-1:1993 must be used. It is believed that the supply industry favours the use of signatures for the exchange of plain text files. (A signature is a sequence of octets sent at the start of an interchange to signal what code format will be used and what octet ordering is going to be used for the transmission of each multi-octet code representing a character.) The other two items in the list can be signalled with the use of escape sequences but are less important for interoperability.
This section contains sample text that may be used within procurement specifications for products that need to support character set operation. The clauses given apply to general purpose products intended for commercial and administrative applications. They may be tailored to the needs of the specific procurement. If the procurement is for specialist applications which may have unusual requirements or may have restricted capabilities, it is recommended that the procurement officer seek expert advice.
Note - Because of the fact that this section is primarily geared at public procurement, and because the laws for public procurement in Western Europe, this section only covers official standards. For other procurement purposes, manufacturer standards may well be used but are not referenced here. For such cases, the reader is referred to the "IBM National Language Support Reference Manual Volume 2 - National Language Design Guide" and to the "Comparisons of Standardized Character Sets for Europe" (see References). Note also that for telecommunication applications, the reader is referred to corresponding ETSI and ITU-T standards.
The section is structured after the model described in section 6. Thus if the requirements are identified in terms of standard specifications and the procurement specification is structured in accordance with the model, then the relevant procurement clauses can easily be looked up.
11.2 Input character repertoire
11.2.1 EN 1923:1997
The following clause should be included in the procurement specification in order to specify input repertoire(s) from EN 1923:1997.
"The product shall support the input repertoire(s) xxxx specified in EN 1923:1998."
where xxxx is one or more of the following:
BL, LL8, BG, BC, BL & BG, BL & BC, BL & BG & BC.
(This guide deprecates the use of the repertoires IVL and IL.)
11.2.2 CEN CWA nnn:1999
The following clause should be included in the procurement specification in order to specify input repertoire(s) from CEN CWA nnn:1999.
"The product shall support the input repertoire(s) xxxx specified in CEN CWA nnn:1999."
where xxxx is one or more of, MES-1, MES-2, MES-3A and MES-3B.
Note - If more than one input repertoire is chosen, the following clause should be included in the procurement specification.
"The product shall be configured for use of the specified input repertoires together with applications as follows:
Repertoires xxxx together with application(s) zzzz."
where xxxx are the repertoires as specified in preceding clauses and zzzz is (are) the name(s) of application(s) as appropriate.
11.3 Output character repertoire
11.3.1 EN 1923:1997
The following clause should be included in the procurement specification in order to specify output repertoire(s) from EN 1923:1997
"The product shall support the output repertoire(s) xxxx specified in EN 1923:1998."
where xxxx is one or more of the following:
BL, LL8, BG, BC, BL & BG, BL & BC, BL & BG & BC.
(This guide deprecates the use of the repertoires IVL and IL.)
11.3.2 CEN CWA nnn:1999
The following clause should be included in a procurement specification in order to select an output repertoire from CEN CWA nnn:1999.
"The product shall support the input repertoire(s) xxxx specified in CEN CWA nnn: 1999."
where xxxx is one or more of, MES-1, MES-2, MES-3A and MES-3B.
Note - If more than one output repertoire is chosen, the following clause should be included in the procurement specification.
"The product shall be configured for use of the specified output repertoires together with applications as follows:
Repertoires xxxx together with application(s) zzzz."
where xxxx are the repertoires as specified in preceding clauses and zzzz is (are) the name(s) of application(s) as appropriate.
11.3.3 Fall-back and other output transformation functions
There may be cases where the processing repertoire contains characters that cannot be rendered by the output repertoire. If any particular fall-back functions or other output transformation functions are requested, one of the following clauses should be included.
"If the processing repertoire contains characters that cannot be rendered by the output repertoire, each such character should be represented in such a way as to indicate that it is not the original character."
or
"If the processing repertoire contains characters that cannot be rendered by the output repertoire, each such character should be represented in such a way as to indicate that it is not the original character and also in such a way as to make it possible for the end user to identify that original character, e.g. by way of identifying its coded representation."
11.4 Processing character repertoire
11.4.1 EN 1923:1997
The following clause should be included in the procurement specification in order to specify processing repertoire(s) from EN 1923:1997
"The product shall support the processing repertoire(s) xxxx specified in EN 1923: 1998."
where xxxx is one or more of the following:
BL, LL8, BG, BC, BL & BG, BL & BC, BL & BG & BC.
(This guide deprecates the use of the repertoires IVL and IL.)
11.4.2 CEN CWA nnn:1999
The following clause should be included in the procurement specification in order to specify processing repertoire(s) from CEN CWA nnn:1999.
"The product shall support the processing repertoire xxxx specified in CEN CWA nnn: 1999."
where xxxx is one or more of MES-1, MES-2, MES-3A and MES-3B
Note - If more than one processing repertoire is chosen, the following clause should be included in the procurement specification.
"The product shall be configured for use of the specified processing repertoires together with applications as follows:
Repertoires xxxx together with application(s) zzzz."
where xxxx are the repertoires as specified in preceding clauses and zzzz is (are) the name(s) of application(s) as appropriate.
11.5 Interchange character repertoire
11.5.1 EN 1923:1997
The following clause should be included in the procurement specification in order to specify interchange repertoire(s) from EN 1923:1997.
"The product shall support the interchange repertoire(s) xxxx specified in EN 1923:1998."
where xxxx is one or more of the following:
BL, LL8, BG, BC, BL & BG, BL & BC, BL & BG & BC.
(This guide deprecates the use of the repertoires IVL and IL.)
11.5.2 CEN CWA nnn:1999
The following clause should be included in the procurement specification in order to specify interchange repertoire(s) from CEN CWA nnn:1999.
"The product shall support the interchange repertoire(s) xxxx specified in CEN CWA nnn:1999."
where xxxx is one or more of MES-1, MES-2, MES-3A and MES-3B.
Note - If more than one interchange repertoire is chosen, the following clause should be included in the procurement specification.
"The product shall be configured for use of the specified interchange repertoires together with applications as follows:
Repertoires xxxx together with application(s) zzzz."
where xxxx are the repertoires as specified in preceding clauses and zzzz is (are) the name(s) of application(s) as appropriate.
11.5.3 Fall-back and other transformation functions
There may be cases where the processing repertoire in the product when sending contains characters that are not contained in the interchange repertoire. If any particular fall-back or other transformation functions are requested, one of the following clauses should be included.
"If the processing repertoire in the product when sending contains characters that are not contained in the interchange repertoire, each such character should be represented during interchange in such a way as to indicate to the receiving system that it is not the original character."
or
"If the processing data in the product when sending contain characters that are not contained in the interchange repertoire, each such character should be represented during interchange in such a way as to indicate to the receiving system that it is not the original character and also in such a way as to make it possible for the end user to identify that original character, e.g. by way of identifying its coded representation."
There may also be cases where the interchange repertoire contains characters that are not contained in the processing repertoire in the product when receiving. If any particular fall-back or other transformation functions are requested, one of the following clauses should be included.
"If the interchange repertoire contains characters that are not contained in the processing repertoire in the product when receiving, each such character should be represented in the latter repertoire in such a way as to indicate to the processing function that it is not the original character."
or
"If the interchange repertoire contains characters that are not contained in the processing repertoire in the product when receiving, each such character should be represented in the latter repertoire in such a way as to indicate to the processing function that it is not the original character and also in such a way as to make it possible for the end user to identify that original character, e.g. by way of identifying its coded representation."
11.6 Additional requirements when using the 8-bit code structure for interchange
If an interchange repertoire has been selected from EN 1923:1997 and the 8-bit code structure is required for interchange, the following clause should be included in the procurement specification.
"For the specified interchange repertoires, the product shall support the 8-bit code structure requirements as specified in EN 1923:1998."
If the user is particularly concerned about the achievement of interoperability in the 8-bit code structure environment, the following clause should be included in the procurement specification.
"The product shall satisfy the conformance requirements of ISO/IEC ISP 12070-1:1996 for operation of the 8-bit code structure."
11.7 Additional requirements when using the multi-byte UCS code structure for interchange
The following requirements should be specified in order to create an environment which maximises interoperability where a general purpose implementation is sought. In many cases interoperability is achieved through the procurement of specific applications which take care of this issue. For such cases, these additional requirements do not apply.
The approach taken is to ask for a minimum requirement on senders and a maximum requirement on receivers.
11.7.1 Levels and coding form
If MES-1 or MES-2 is chosen as the interchange repertoire, the following clause should be added to the procurement specification.
"For sending, the product shall support at least the level-1 operation using at least the UCS-2 form as specified in ISO/IEC 10646-1:1993."
If the MES-3A or MES-3B is chosen as the interchange repertoire, the following clause should be added to the procurement specification.
"For sending, the product shall support the level-3 operation using at least the UCS-2 form as specified in ISO/IEC 10646-1: 1993."
Regardless of which repertoire is specified, the following clause should be included.
"For receiving, the product shall support the level-3 operation using at least the UCS-2 form, the UCS-4 form and the UTF-8 transformation format as specified in ISO/IEC 10646-1:1993."
11.7.2 Ordering of octets
In the UCS code structure, characters are generally represented by multiple octets. The order in which those octets are sent affects interoperability. The following clauses should be included in the procurement specification.
"For sending, the product shall support at least the normal ordering of octets for each character sent as specified in ISO/IEC 10646-1:1993."
"For receiving, the product shall support both the normal ordering and the reverse ordering of octets for each character sent as specified in ISO/IEC 10646-1:1993."
11.7.3 Signatures
For sending unstructured text information, the appropriate signatures should be used so that the receiver may understand what format is being used and in which order character octets are being sent. The following clause should be included in the procurement specification.
"For sending, the product shall support the use of the appropriate signatures as specified in ISO/IEC 10646-1:1993."
For receiving unstructured text information, all the appropriate signatures should be accepted so that the receiver may understand what format is being used and in which order character octets are being sent. The following clause should be included in the procurement specification.
"For receiving, the product shall support the use of all signatures as specified in ISO/IEC 10646-1:1993."
CEN (Comité Européen de Normalisation) is the organisation responsible for standardisation in Europe. Details of CEN and its operations may be found at http://www.cenorm.be. TC 304 is a technical committee within CEN responsible for European Localisation Requirements to give its proper title.
The work of TC304 is standardisation in the field of information and communication technologies as applied to character sets and related cultural elements (such as date and time conventions, numeric formatting), to ensure that European localisation requirements are satisfied. The work concerns the areas of identification, manipulation and coded representation of character data and its input, interchange and rendition by electronic means.
Within this scope, TC304 is currently active in the following areas:
It is anticipated that, in the near future, TC304 will become active in the area of Language Technology by encouraging the promotion of specifications resulting from European Language Technology research and development projects. Some of these specifications may develop into European or even international standards.
More information concerning TC304 may be found at http://www.stri.is/tc304.
13 References
The Unicode Standard, Version 2.0
This standard defines a character code for code identical to that contained in ISO/IEC 10646-1:1993 as amended by the amendments 1 through 7.
The Unicode Standard, Version 2.1
The Unicode Consortium, 1998
Available at http://www.unicode.org/unicode/ reports/tr8.html
Manual: Standards for the electronic interchange of personal data: Part 5: Character sets (1995)
Author: J W van Wingen
ISBN 90-5414-019-4
Published by the Directorate of Departmental Relations and Provision of Information
Directorate-General for Public Information
Ministry of the Interior
P.O. Box 20011
250 EA The Hague
Netherlands
This manual was produced for the Ministry of the Interior in the Netherlands. It provides the uninformed reader with an overview of character sets and their standards which in some respects is more extensive than this guide. It also makes certain recommendations targeted at the use of character sets for administrative purposes within the public sector in the Netherlands. It provides an alternative view to some of the issues on the use of character sets and further detailed technical information.
Comparisons of Standardized Character Sets for Europe (1996)
Author: K I Larsson
ISBN 91-7220-275-0
Published by Statskontoret
The Swedish Agency for Administrative Development
Box 2280, 103 17 Stockholm
Sweden
Orders may be directed by e-mail to [email protected]
This document was produced for Statskontoret in Sweden. It provides in tabular form a detailed comparison of character sets, both standardised and manufacturer defined. The character sets are mainly 8-bit coded sets and the coverage is comprehensive covering most of the Latin based sets likely to be encountered in Europe. It provides a useful source of code table/code page specification, especially of the manufacturer code pages.
An operational model for characters and glyphs
ISO/IEC 15285
May be obtained from any national member body of ISO.
This technical report provides a framework for discussing characters and glyphs. The framework is applicable to a variety of coded character sets and glyph identification schemes.
Language automation worldwide: The development of character set standards (19xx).
ISBN: 1-870095-0-4This document covers all scripts in use worldwide, with a considerable emphasis on character sets for European scripts.
IBM Character Data Representation Library
Character Data Representation Architecture
Level 2 - Reference (1993)
Publication Number SC09-1390-01
To quote: "The overall objective of CDRA is to define a method of assigning and preserving the meaning and rendering of coded graphic characters through various stages of processing and interchange." This is a comprehensive architectural document which provides a basis for consistent implementation of character set support across a range of IBM platforms. It is very detailed but will reward the dedicated reader who is intent on researching character set issues in depth from an implementation point of view.
IBM National Language Support Reference Manual Volume 2 - National Language Design Guide (1994)
Publication Number SE09-8002-03
To quote: "This guide is directed at developers, planners, and vendors of computer products intended for international markets". Appendix I contains details of IBM code pages, both for EBCDIC and for PCs.
Letter Database
Indrek Hein
http://www.eki.ee/letter/
This website contains a comprehensive set of information relating to character sets. Some of this is accessed by internal links and the remainder by search engine.
Annexes
Annex B The Universal Character Set (UCS)